The ability to converse with computers has for a long time been the realm of science fiction – 2001 and HAL 9000 (or if you were a child of the 80’s maybe the Knight Industries Two Thousand). In the past few years we’ve started to see speech interaction become much more common thanks to services like Siri on iOS devices, Dictation in OS X and Cortana on Windows. When you think that we’re increasingly starting to access the web via mobile devices, all of which have a microphone built in to them, it makes sense that speech should be a natural form of input compared to typing on a tiny keyboard.
Recently browsers have started to allow developers access to the Web Speech API. The Web Speech API is a JavaScript API that allows developers to incorporate speech recognition or provide text to speech features within their web based applications. At the moment, as it’s still relatively experimental so doesn’t have thorough browser support. Currently, Chrome is the only major browser to support this feature.
You may have noticed that when you visit the Google homepage in Chrome there is a microphone in the corner of the search box.

Clicking on the microphone allows you to dictate a query to Google, rather than typing in your query. The speech recognition doesn’t happen within the browser. The API takes your speech, sends it to Google for analysis & returns a string of text as to what it has interpreted the speech as. It’s a similar process if you’ve enabled Dictation in OSX, your speech is sent to Apple for analysis (there are options for enabling offline recognition). The need for a third party speech recognition service is one reason why browser support is limited. At the moment there isn’t a universal recognition system that these browsers can point to, the recognition is tied into where ever the browser maker decides the recognition is going to take place.
Faking natural language processing
This is the bit where all those researching natural language processing start to roll their eyes & start laughing at me. This section is called faking it and is a very simplistic approach to natural language processing. It’s by no means perfect, but it will demonstrate what you can quite easily do with hardly any effort.
For this demonstration I’ve built an application to demonstrate the Web Speech API and to see if we can make searching a collection an easier process by using speech and ‘faking’ some natural language processing. I’ve built the application to query Trove using it’s API.
How does this work?
Trove provides a perfect example for searching as it’s all essentially fielded queries. To start with there are all the various zones that can be searched upon (pictures, books, maps etc). In addition to the zones, we can target searches to be limited to fielded data like titles, dates and creators. Compared to a broad search interface like Google’s, our search interfaces are dealing with a limited number of combinations limited to the use of these fields.
In our library catalogues or museum collection searches we typically try to make sense of the multitude of fields by grouping them in a related manner.
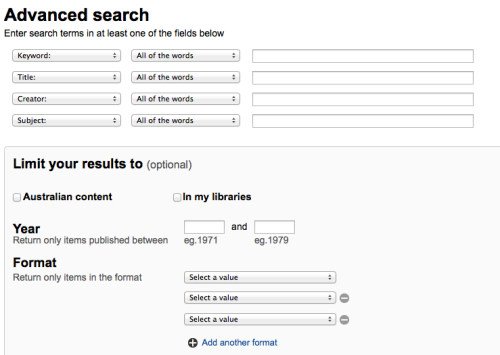
This is clear, but still quite complex. I’ve previously presented about the difficulties users can encounter trying to successfully navigate these interfaces. Take a sample search “Paintings by Sidney Nolan between 1946 and 1948”. To successfully submit the search requires the user to select a zone to search (Pictures), entering queries into 3 different sections of the form (once in the creator text field and 2 date entries), and interacting with 2 drop down menus (the creator and selecting a format). It’s not a simple task, however, the search term itself isn’t exactly complex. What if we could programatically break down that query automatically into the components that make up these fields?
- Paintings
- Sidney Nolan
- 1946-1948
This can be achieved by passing the query through a set of filters to match patterns that exist in a term. These filters are known as regular expressions. Let’s take a look at just the way we express dates in English & look at how we can detect these patterns and convert them into a query that the Trove API will understand.
| English phrase | Regular Expression | Trove API speak |
|---|---|---|
| in 1993 | (in|from) ([1-2][0-9]{3}) | date:[1993 TO 1993] |
| from 1933 | (in|from) ([1-2][0-9]{3}) | date:[1993 TO 1993] |
| before 1962 | (before|pre) ([1-2][0-9]{3}) | date:[* TO 1962] |
| pre 1918 | (before|pre) ([1-2][0-9]{3}) | date:[* TO 1918] |
| after 2001 | (after|post) ([1-2][0-9]{3}) | date:[2001 TO *] |
| post 1945 | (after|post) ([1-2][0-9]{3}) | date:[1945 TO *] |
| in the 1960s | (in|from) the ([1-2][0-9]{2}[0][\’]?[s]) | decade:196 |
| from the 1960’s | (in|from) the ([1-2][0-9]{2}[0][\’]?[s]) | decade:196 |
| between 1932 and 1956 | (between|from) ([1-2][0-9]{3}) (and|to) ([1-2][0-9]{3}) | date:[1932 TO 1956] |
| from 1939 to 1945 | (between|from) ([1-2][0-9]{3}) (and|to) ([1-2][0-9]{3}) | date:[1939 TO 1945] |
In regular expressions the pipe character “|” indicates OR. A year can (roughly) be expressed by the first character being a 1 or 2 followed by 3 characters that are between 0 and 9 e.g.: ([1-2][0-9]{3}). By testing for these patterns matching a query, it’s relatively easy to extract date information from our query.
Likewise we can look at the start of the query to look for what type of search a user is looking for: books by, pictures of, sound recordings of, photos by, photos taken by, paintings by, maps made by, braille copy of etc etc. By matching these we can determine the “major zone” a query might be taking place in e.g.: book, picture, map etc and possibly a format that is a subset of these major zones e.g.: art work, sound, audiobook, braille, etc.
In addition to the type of zone to search on, it’s also possible to break down the type of search. The terms of “about” or “by” can indicate that a search for “photos of” is a subject search while a search for “photos by” is searching for a creator.
Let’s take a brief look at some common terms that people might use when asking a question and look at how we can analyse these sentences to turn them into a query that a service like Trove would understand. We would typically ask a question along the lines of:
- Pictures of Sydney Harbour Bridge
- Pictures of Sydney Harbour Bridge before 1930
- Pictures of the Sydney Harbour Bridge between 1985 and 1992
- Photos of the Sydney Harbour Bridge from the 1920’s
- Books by J.K. Rowling
- Audio books of Harry Potter
- Braille version of Harry Potter and the philosopher’s stone
- Pictures of Canberra from 1926
- Pictures taken in 1926 (or Pictures from 1926)
- Maps of Sydney before 1850
- Recordings of Hubert Opperman
- ISBN equals 0747545723
2 methods of input for the price of 1
It’s not just about speech. Remember that not every browser supports speech input. Luckily, since the result returned from the speech recognition service is a string of text, this is identical to what could be typed into a search box. This simplistic natural language processing also works when you type a phrase in English – making this process available to any user using any browser.
Not seeking perfection
This really is a demonstration and only uses a selected portion of possible combinations to query – mostly format and date based. There’s obvious issues of false positives. If you were looking for a book with a title of “Photographs of Sydney”, you would get photographs rather than the book. However, we could display other results and list books with this term as a title in facets. There are ways around this.
Maybe with a bit more refining and experimenting, these techniques could greatly assist in providing a simpler interface for interacting with our collections. Have a play with my Ask Trove application and think about how this concept might be able to be incorporated into other applications.